
Jeżeli macie konto na Facebooku czy Instagramie, to zapewne już widzieliście najnowsze internetowe wyzwanie – 10 Year Challenge (#10YearChallange).
O co chodzi w #10YearChallenge?
W skrócie: osoby zamieszczają swoje dwa zdjęcia — jedno sprzed 10 lat, a drugie zrobione obecnie z hasztagiem #10YearChallenge.
Zazwyczaj zdjęcia prezentują nasze pozytywne zmiany w życiu. Nie jestem pewna, od kiedy trwa cała ta zabawa, ale moja tablica fb jest już tym zarażona. Widziałam zdjęcia celebrytów 2009 kontra 2019, znajomych i zupełnie przypadkowych osób.
Fotografie pokazują, jak bardzo zmieniliśmy się przez lata, są okazją do refleksji. Mogą być początkiem dyskusji ze znajomymi, przywoływaniem wspomnień z okoliczności powstania zdjęcia czy wreszcie sposobem na zwiększenie zasięgów w social mediach. To wszystko sprawia, że hasztag #10YearChallenge zdobył wiralową popularność. Według Forbesa opublikowano już ponad 5 milionów postów z wyzwaniem, a ludzie cały czas chętnie biorą w nim udział.

Trening dla sztucznej inteligencji
Z zasady nie biorę udziału w challengach. Zazwyczaj są one niezbyt interesujące, ale to jedno wydaje mi się na tyle ciekawe, że postanowiłam o nim napisać. Zaczęło się od tego tweeta, który dał mi do myślenia:
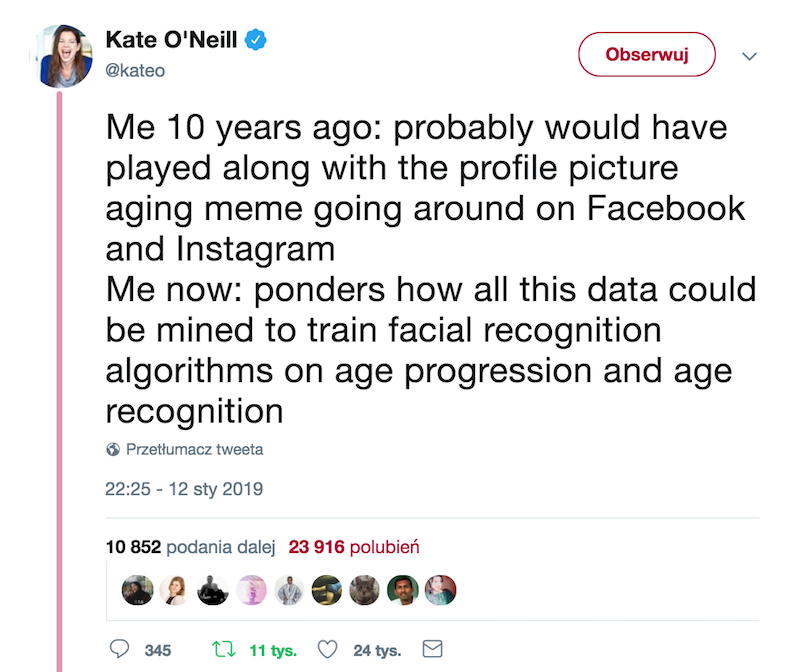
Kate O’Neill, autorka książki „Tech Humanist”, zwróciła uwagę, że wyzwanie to świetny materiał dla uczenia maszynowego!
Ja 10 lat temu: prawdopodobnie wzięłabym udział w wyzwaniu kontem na Facebooku i Instagramie
Ja dzisiaj: zastanawiam się, w jaki sposób można zebrać wszystkie te dane, aby wytrenować algorytmy rozpoznawania twarzy na temat progresji wiekowej i rozpoznawania wieku.
To prawda, gdyby trenować sieć neuronową, czy sztuczną inteligencję do rozpoznawania twarzy, cech związanych z wiekiem i upływu czasu, taki zestaw danych o ustalonej odległości czasowej jest wręcz idealny.
To niesamowite, że przez kilka dni Facebook i Instagram zmieniły się w ogromne, darmowe, biometryczne repozytorium. Wystarczy jedynie użyć wyszukiwarki na hasło hashtaga #10YearChallenge, by błyskawicznie dostać zestaw danych, które wręcz proszą się o dalszą analizę.
Czy Facebook wykorzystuje #10YearChallenge?
Podobno nie. Zresztą, w jaki sposób sam hasztag miały coś zmienić?
Te dane są już dostępne. Facebook ma nie tylko wszystkie zdjęcia profilowe, ale też dane o zachowaniach użytkowników oraz tym jak te dane zmieniały się w ciągu 10 lat. Jeśli chodzi o big data, to Facebook jest jednym z największych światowych graczy.
Facebook oficjalnie zaprzeczył, że ma z wyzwaniem „10 year challenge” cokolwiek wspólnego:

Wiem, że w Internecie powstało sporo postów, które straszą sztuczną inteligencją. Nie o to chodzi. AI to technologia, która będzie się rozwijać, a ludzie powinni o tym wiedzieć. Warto się zastanowić ile treści o sobie udostępniamy? Jak daleko pozwalamy wchodzić w nasze życie prywatne osobom z zewnątrz? Jak nasze dane osobowe są przetwarzane, łatwe do powiązania z wszystkim innym o nas? To są informacje, które udostępniamy firmom bez refleksji. Jak mogą być dalej wykorzystywane?

Czy zdjęcia z wyzwania są lepsze do uczenia maszynowego?
Baza fb zawiera ogrom zdjęć profilowych, więc porównanie dat nie powinno być problemem. Użytkownicy nie zawsze używają swojego najnowszego zdjęcia jako profilowe. Czasem wstawiają zdjęcia z przeszłości. Nic nie szkodzi. Zdjęcia cyfrowe posiadają ukryte informacje szczegółowe EXIF (rodzaj aparatu, datę wykonania zdjęcia czy lokalizacje, jeśli urządzenie miało GPS). Co prawda zostają nam jeszcze przypadki, gdy zdjęcie to np. skan zdjęcia analogowego z przeszłości czy dane EXIF autor postanowił usunąć. Do tego dochodzi mnóstwo profilówek jako przypadkowe grafiki z Internetu.
Zalety #10YearChallange pod kątem machine learningu
Dostajemy wstępnie wyselekcjonowane obrazy, które:
- dotyczą tej samej osoby, zazwyczaj jej twarzy.
- zostały wykonane ze znanym odstępem czasu
- często zawierają też dokładne daty („ja: 20.11.2009, ja: 17.01.2019”)
- są wzbogacone o dodatkowy kontekst – w wielu przypadkach, pojawiają się informacje dotyczące miejsca i osób towarzyszących („czerwiec 2009: obrona pracy inżynierskiej, Uniwersytet Adama Mickiewicza w Poznaniu, grudzień 2018 Paryż: zaręczyny z @Anna Kowalska”).
Wykorzystujemy web scrapping, budujemy bazę, bierzemy znane algorytmy rozpoznawania twarzy i można zacząć się bawić…
Oczywiście, nadal te dane będą zawierać sporo śmieci, tzw. szumu. Ludzie wrzucają różne zdjęcia z hasztagiem #10YearChallange: swoje zwierzaki, celebrytów (szczególnie tych, którzy zamiast się starzeć przeszli kolejne -naście operacji plastycznych), nieśmiertelne postacie popkultury czy memy.

Możliwości czy zagrożenia?
Dane te na pewno mogłyby przyczynić się do rozwoju kryminalistyki, w tym progresji wiekowej. To niezbędne narzędzie policji, która poszukuje osób zaginionych. Obecnie specjalne laboratoria zajmują się postarzaniem portretów. W oparciu o zdjęcia otrzymane od rodziny, portrety pamięciowe i wiedzę o procesach starzenia powstają zaktualizowane obrazy pozwalające na skuteczne poszukiwania zaginionych. To samo dotyczy przestępców, którzy przez lata są poszukiwani listem gończym. Nawet na podstawie rysunku z portretu pamięciowego, policja może otrzymać komputerowo wygenerowane „zdjęcie” poszukiwanego.

Na podstawie algorytmu rozpoznawania twarzy możliwe jest targetowanie reklam. Mogą być dobierane nie tylko na podstawie wieku, zainteresowań czy polubień. Co powiecie na precyzyjną reklamę środka na porost włosów, skierowaną do osoby, która ma zakola? Niby nic groźnego.
Wiemy, że Facebook udostępnia i zarabia na danych użytkowników. W zeszłym roku odbywał się głośny proces w sprawie wycieków danych. Gazety i portale prześcigały się w doniesieniach z przesłuchania Marka Zuckerberga. Cofnijmy się na chwilę. Jak zbierano dane, które pozwalają precyzyjnie profilować, a przez to wpływać na zachowania ludzi? Pozornie niegroźne sposoby: aplikacje, quizy i facebookowe gry zaprojektowano w celu gromadzenia wrażliwych danych i użytkownikach. Wiele zostało stworzonych do manipulowania opinią publiczną. Najgłośniejsza sprawa dotyczy pobrania danych ponad 70 milionów użytkowników Facebook przez Cambridge Analytica, co wpłynęło na wynik wyborów w USA.
Twarz na sprzedaż
Pod koniec 2016 roku Amazon wprowadził technologię rozpoznawania twarzy w czasie rzeczywistym pod nazwą Rekognition project jako część usług AWS (Amazon Web Services). Następnie swoje rozwiązanie zaczęli sprzedawać bezpośrednio organom ścigania i agencjom rządowym. Interweniowała organizacja The American Civil Liberties Union, która wskazała, że taka kontrola narusza prywatność obywateli. Technologię Amazona można wykorzystać nie tylko do śledzenia osób podejrzanych o popełnienie przestępstwa. Pod obserwacją mogą być osoby niepopełniające przestępstw, takie jak protestujący i inni osoby, uznane przez policję za uciążliwe.

Całkiem niedawno Google otrzymało pozew za udostępnianie danych biometrycznych. Kobieta została nieświadomie uchwycona na 11 zdjęciach zrobionych smartfonem z Androidem przez użytkownika Google Photos. Pozew został oddalony, ponieważ powódka nie poniosła „konkretnych szkód”. Mimo to wiadomość wzbudziła słuszne obawy o prywatność. Teraz wyobraźmy sobie, że jesteśmy w stanie znaleźć w ciągu kilku sekund dane osób, które był w tle naszych wakacyjnych zdjęć sprzed 10 lat.
Refleksja nad #10YearChallange
Bez względu na pochodzenie wyzwania, ukryte intencje, czy ich brak, nie zaszkodzi zadbać o ustawienia prywatności. Może to dobry czas, by zastanowić się: ile swojego życia chcemy udostępniać podmiotom trzecim. Treści, które tworzymy, mogą być dalej używane już poza naszą kontrolą. Czy jeśli znaleziono by dowody, że wyzwanie rzeczywiście zbiera pary zdjęć użytkowników do badań progresji wieku i szkolenia algorytmu, udostępnisz swoje zdjęcie?
Szczerze, kogo obchodzą wasze zdjęcia sprzed 10 lat? Chyba że siedzicie na rodzinnej imprezie i złośliwe ciotki muszą powspominać „patrz… ale Ci się przytyło!”. Spróbujcie bardziej świadomie myśleć o swoim „cyfrowym śladzie”.
Rozpoznawanie twarzy
Pokażę jak nie wiele potrzeba, aby zacząć. Do zabawy w rozpoznawanie twarzy nie potrzeba wiele.
Na start: Python i OpenCV (jest najpopularniejszą biblioteką do rozpoznawania obrazów).
Na Githubie udostępniłam repo Face Detection, gdzie możecie przetestować prosty kod korzystający z OpenCV oraz dostępnych już gotowych, wytrenowanych klasyfikatorów (Haar cascades)
Moim pythonującym czytelnikom zostawiłam mały prezent w readme — pomysły na dalszy rozwój skryptu. Stwórzcie fork repozytorium i spróbujcie wdrożyć pomysły z sekcji TO DO!
Możecie pokusić się o samodzielne stworzenie danych uczących.

Sprawdź również:
– Sieci neuronowe w JavaScript
– Chcesz się nauczyć Pythona? Na blogu znajdziesz darmowy kurs Pythona od podstaw
komentarze: 0