
Ucząc się programowania prędzej czy później natkniecie się dziwne krzaczki, które naprowadzą was na nowe pojęcie – kodowanie znaków albo po prostu ASCII / UNICODE.
Co nas dzisiaj czeka?
Zaczniemy od definicji – co to jest kodowanie znaków?
System binarny
Musimy zacząć od podstaw, a te cofają nas do samego działania pamięci komputera. Komputer przechowuje informacje za pomocą zer i jedynek. Taki sposób nazywamy systemem binarnym lub dwójkowym. Podstawowymi pojęciami związanymi z tym systemem są bit oraz bajt.
Bit – jest najmniejszą jednostką w świecie cyfrowym, odpowiada stanowi komórki pamięci. Bit przyjmuje wartość zero lub jeden.
Ciąg ośmiu bitów (czyli zer i / lub jedynek) nazywamy bajtem (byte).
1 BAJT = 8 BITÓW
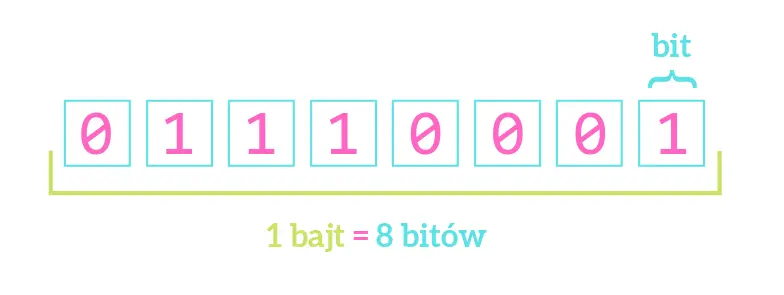
Bajt daje aż 256 różnych kombinacji bitów. Stąd pozwala na zapisanie binarnie liczb od 0 do 255. Innymi słowy każdy bajt to liczba w przedziale od 0 do 255, ale zapisana za pomocą zer i jedynek np. 00000000 to liczba zero, 00000001 to jeden. Dwa natomiast zapiszemy jako 00000010. Dlaczego? Stan bitów odczytujemy od prawej do lewej, a kolejne pozycje odpowiadają, kolejnym potęgom 2. Spójrzcie na przykład:
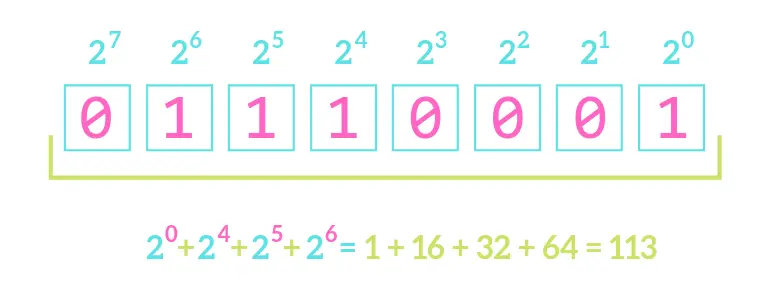
A litery?
Liczby zapisane binarnie mogą też być interpretowane jako litery. Przykładowo 0100 0001 odpowiada 65 w systemie dziesiątkowym, co komputer zinterpretuje i wyświetli jako duże A.
W Pythonie możemy wykorzystać metodę chr()
'A'
>>> chr(66)
'B'
>>> chr(97)
'a'
>>> chr(98)
'a'
oraz metodę ord(), aby poznać liczę odpowiadającą literze
65
>>> ord('a')
97
Podobnie w innych językach np. w ruby
'A'
irb > 'a'.ord
97
czy podobne operacje w JavaScripcie – charCodeAt i fromCharCode.
65
> String.fromCharCode(97,98,99);
'abc'
Wszystko to do tej pory wygląda dobrze.
Pytanie tylko skąd wiadomo jaka liczba odpowiada danej literze?
Standardy kodowania znaków
Aby pomóc w interpretacji liczb binarnych stworzono szyfry podstawieniowe zwane standardami. Istnieje kilka standardów kodowania znaków. Być może słyszeliście o UNICODE, ale wcześniej było jeszcze kilka innych.
ASCII
Pierwszym szeroko rozpowszechnionym standardem kodowania był ASCII. Pojawił się w 1960 za sprawą American National Standards Institute (ANSI), a jego korzenie sięgają kodu telegraficznego.
Tablica znaków ASCII to tabela składająca się z 128 znaków (7-bitowy zapis), w tym dużych i małych liter oraz znaków specjalnych jak np. spacja. Chcąc się odwołać do danego znaku należało podać jego numer w tabeli np. „A” to znany nam już numer 65, co daje w systemie binarnym 100 0001.
Z czasem okazało się, że ASCII nie jest doskonałe. Stworzone na bazie języka angielskiego nie uwzględniało znaków używanych w innych językach, dlatego w ASCII niemożliwe jest kodowanie polskich znaków dialektycznych czy znaków języka chińskiego.
Standard ASCII stał się jednak wzorcem dla kolejnych standardów. Możecie zauważyć, że pierwsze 127 znaków jest spójne dla pozostałych standardów w tym wpisie, stąd w literaturze noszą miano rozszerzeń ASCII.
Tablica ASCII
– kolejno w systemie dziesiętnym, szesnastkowym, dwójkowym, ósemkowym i kodowany znak
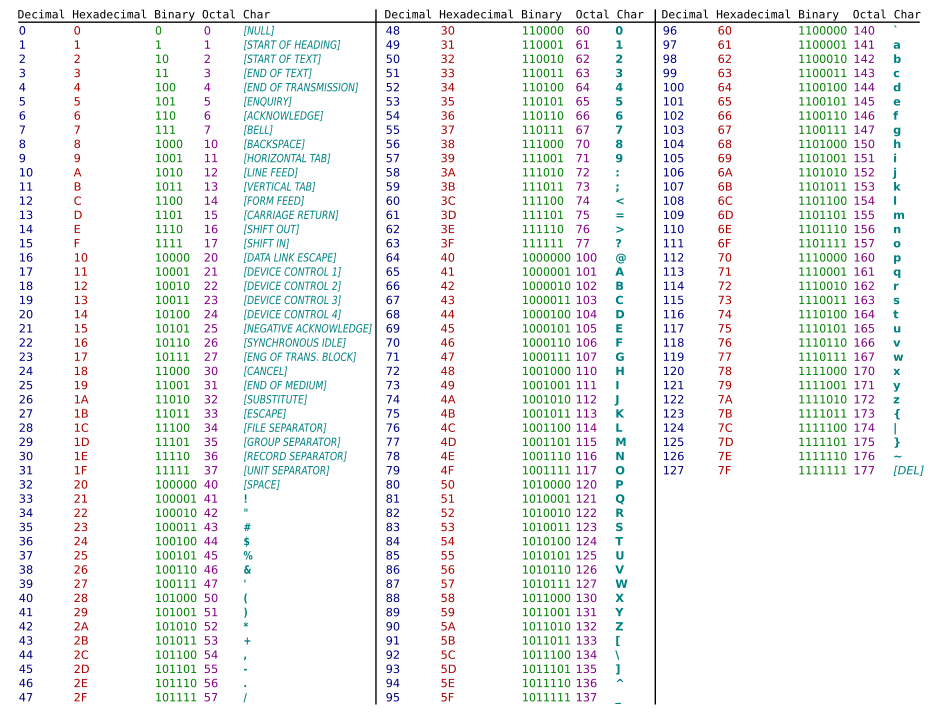
Tablica kodów ASCII
|
Kod dziesiętny |
Znak |
Kod dziesiętny |
Znak |
Kod dziesiętny |
Znak |
Kod dziesiętny |
Znak |
|
0 |
NUL |
32 |
Space |
64 |
@ |
96 |
` |
|
1 |
SOH |
33 |
! |
65 |
A |
97 |
a |
|
2 |
STX |
34 |
„ |
66 |
B |
98 |
b |
|
3 |
ETX |
35 |
# |
67 |
C |
99 |
c |
|
4 |
EOT |
36 |
$ |
68 |
D |
100 |
d |
|
5 |
ENQ |
37 |
% |
69 |
E |
101 |
e |
|
6 |
ACK |
38 |
& |
70 |
F |
102 |
f |
|
7 |
BEL |
39 |
’ |
71 |
G |
103 |
g |
|
8 |
BS |
40 |
( |
72 |
H |
104 |
h |
|
9 |
TAB |
41 |
) |
73 |
I |
105 |
i |
|
10 |
LF |
42 |
* |
74 |
J |
106 |
j |
|
11 |
VT |
43 |
+ |
75 |
K |
107 |
k |
|
12 |
FF |
44 |
, |
76 |
L |
108 |
l |
|
13 |
CR |
45 |
– |
77 |
M |
109 |
m |
|
14 |
SO |
46 |
. |
78 |
N |
110 |
n |
|
15 |
SI |
47 |
/ |
79 |
O |
111 |
o |
|
16 |
DLE |
48 |
0 |
80 |
P |
112 |
p |
|
17 |
DC1 |
49 |
1 |
81 |
Q |
113 |
q |
|
18 |
DC2 |
50 |
2 |
82 |
R |
114 |
r |
|
19 |
DC3 |
51 |
3 |
83 |
S |
115 |
s |
|
20 |
DC4 |
52 |
4 |
84 |
T |
116 |
t |
|
21 |
NAK |
53 |
5 |
85 |
U |
117 |
u |
|
22 |
SYN |
54 |
6 |
86 |
V |
118 |
v |
|
23 |
ETB |
55 |
7 |
87 |
W |
119 |
w |
|
24 |
CAN |
56 |
8 |
88 |
X |
120 |
x |
|
25 |
EM |
57 |
9 |
89 |
Y |
121 |
y |
|
26 |
SUB |
58 |
: |
90 |
Z |
122 |
z |
|
27 |
ESC |
59 |
; |
91 |
[ |
123 |
{ |
|
28 |
FS |
60 |
< |
92 |
\ |
124 |
| |
|
29 |
GS |
61 |
= |
93 |
] |
125 |
} |
|
30 |
RS |
62 |
> |
94 |
^ |
126 |
~ |
|
31 |
US |
63 |
? |
95 |
_ |
127 |
DEL |
Wartość 13 ma przyporządkowany CR (carriage return), inaczej znak end czy EOL (end of line) najprościej to kod ASCII enter – bin: 000 1101.
Wartości 9 odpowiada ASCII tab (tabulacja) – bin: 000 1001.
W ASCII znak and (&) ma przyporządkowaną wartość 38 – bin: 010 0110.
ANSI i ISO
Podjęto próbę rozwiązania problemu z zapisem znaków diakrytycznych występujących w innych językach. Tabela ASCII została rozszerzona do 256 znaków, co było możliwe dzięki wykorzystaniu 8-bitowego systemu zapisu liczb zamiast tylko 7 bitów (Window-1250 od Microsoftu i norma ISO-8859 stworzona przez ECMA).
Mimo to 256 było nadal zbyt małą liczbą, by uwzględnić wszystkie znaki specjalne, jakie istnieją we wszystkich językach, dlatego Microsoft zaproponował osobne wersje tabel ze znakami dla różnych grup językowych zwane stronami kodowymi (ang. ANSI code page). Jak wspomniałam, pierwsze 128 znaków bazuje na ASCII, reszta to znaki potrzebne do zapisu języka, którego dotyczy dana strona kodowa.
Strony kodowe mają przypisane specjalne numery np. Windows-1250 standard środkowoeuropejski, Windows-1251 odpowiada cyrylicy, Windows-1252 to standard zachodnioeuropejski, Windows-1253 koduje greckie znaki, Windows-1256 arabskie.

Ciekawostka: Windows-1252 jest prawdopodobnie najczęściej używanym 8-bitowym kodowaniem znaków na świecie. We wrześniu 2019 r. 0,6% wszystkich stron internetowych zadeklarowało korzystanie z systemu Windows-1252, ale jednocześnie 2,9% korzystało z ISO 8859-1 (0,6% z top 1000 stron www), które według standardu HTML5 jest tym samym kodowaniem. Oznacza to, że na dzień dzisiejszy 3,5% stron wciąż korzysta z Windows-1252 ANSI encoding.
Wydawało się, że wystarczy wybrać odpowiedni język i problem z kodowaniem znaków znika.
Tylko co zrobić w przypadku, gdy w tekście pisanym w jednym języku pojawia się potrzeba wstawienia symbolu z innego? Np. w tekście w języku angielskim chcemy zamieścić specjalne litery takie jak znaki chińskie i greckie.
Kolejnym problemem było istnienie wielu równoległy standardów. Odpowiednikiem stron kodowych ANSI (tylko nazwa, nie są normowane przez ANSI) był wspomniany standard ISO 8859, częściowo kompatybilny z ANSI, jednak wciąż zapis w jednym systemie, mógł powodować błędy odczytu w drugim.
Z ilu liter składa się polski alfabet?
Jeśli się przyjrzymy, podstawowy alfabet angielski zawiera 26 liter (ISO basic latin). Język polski korzysta z 32 liter i zawiera te same litery co angielski (za wyjątkiem Q, V, X) oraz 9 znaków dialektycznych.
Kodowanie polskich znaków znajduje się na stronie kodowej Windows-1250 lub jako cp-1250 razem np. z czeskim, słowackim czy węgierskim. Odpowiednikiem Windows-1250 w normie ISO jest ISO 8859-2. Niestety nie są one w 100% kompatybilne. Zresztą zobaczcie sami.

Kodowanie polskich liter ze znakami diakrytycznymi w standardach Windows-1250 oraz ISO 8859-2:
| Standard | Ą | Ć | Ę | Ł | Ń | Ó | Ś | Ź | Ż |
|---|---|---|---|---|---|---|---|---|---|
| Windows-1250 | 165 | 198 | 202 | 163 | 209 | 211 | 140 | 143 | 175 |
| ISO-8859-2 | 161 | 198 | 202 | 163 | 209 | 211 | 166 | 172 | 175 |
| Standard | ą | ć | ę | ł | ń | ó | ś | ź | ż |
|---|---|---|---|---|---|---|---|---|---|
| Windows-1250 | 185 | 230 | 234 | 179 | 241 | 243 | 156 | 159 | 191 |
| ISO-8859-2 | 177 | 230 | 234 | 179 | 241 | 243 | 182 | 188 | 191 |
Jak widać strony językowe nie rozwiązały wszystkich problemów, chociaż zbliżyły nas do rozwiązania.
UNICODE
Tak docieramy do UNICODE – The Unicode Standard.
Historia pokazała, że potrzebny będzie jeden, spójny system kodowania znaków, który będzie zawierać wszystkie możliwe symbole istniejące w językach świata. Powstała kolejna tabela, kolejny standard – UNICODE.
Koncepcja Unicode pojawiła się 1988, ale prace nad oficjalną publikacją trwały 3 lata. Unicode na początku składał się z 7161 znaków (w tym 127 to tabela znaków ASCII), natomiast najnowsza wersja z maja 2019 to repozytorium aż 137994 znaków. Nie jest to bynajmniej zamknięta grupa, liczba znaków nadal rośnie.
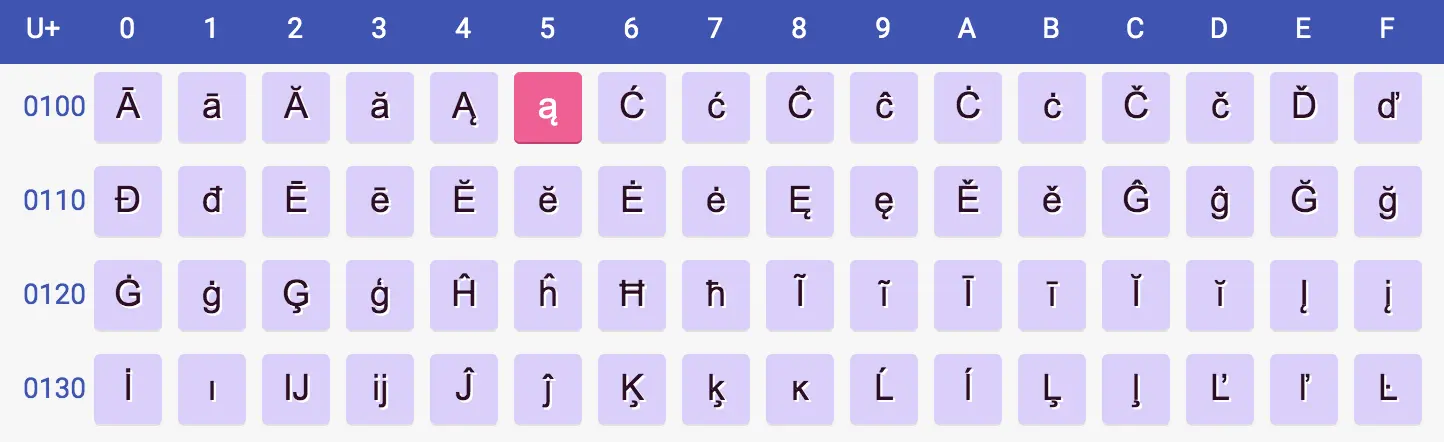
ma przypisaną wartość liczbową 0×105 (U+0105).
Mówiliśmy wcześniej, że 8 bitów pozwala na 256 kombinacji, czyli za pomocą 1 bajtu można zakodować 256 znaków.
W jaki sposób można zatem zapisać 137994 znaków UNICODE?
Wystarczy użyć większej ilości bajtów. Istnieje kilka sposobów kodowania tekstu, czyli konwersji wartości liczbowej z tablicy Unicode do postaci bitowej. Są to kodowania UTF: UTF-8, UTF-16 i UTF-32.
UTF-8
W UTF-8 znaki nie mają stałej długości bitów, przyjmują od 1 do 4 bajtów. Kodowanie UTF-8 jest kompatybilne z ASCII – pierwsze znaki Unicode, czyli 127 znaków tabeli ASCII koduje się jedno-bajtowo. Reszta jest zapisywana kolejno dwu, trzema, czterema, pięcioma i sześcioma bajtami. UTF-8 jest najbardziej ekonomicznym i najpopularniejszym ze sposobów zapisu wartości liczbowej z tablicy Unicode do postaci bitowej.
W UTF-8 polskie znaki dialektyczne są kodowane przez 2 bajty
|
Litera |
Kod |
||
|
heksadecymalny |
dziesiętny |
binarny |
|
|
ą |
0105 |
261 |
00000001 00000101 |
|
ć |
0107 |
263 |
00000001 00000111 |
|
ę |
0119 |
281 |
00000001 00011001 |
|
ł |
0142 |
322 |
00000001 01000010 |
|
ń |
0144 |
324 |
00000001 01000100 |
|
ó |
00F3 |
243 |
00000000 11110011 |
|
ś |
015B |
347 |
00000001 01011011 |
|
ź |
017A |
378 |
00000001 01111010 |
|
ż |
017C |
380 |
00000001 01111100 |
|
Ą |
0104 |
260 |
00000001 00000100 |
|
Ć |
0106 |
262 |
00000001 00000110 |
|
Ę |
0118 |
280 |
00000001 00011000 |
|
Ł |
0141 |
321 |
00000001 01000001 |
|
Ń |
0143 |
323 |
00000001 01000011 |
|
Ó |
00D3 |
211 |
00000000 11010011 |
|
Ś |
015A |
346 |
00000001 01011010 |
|
Ź |
0179 |
377 |
00000001 01111001 |
|
Ż |
017B |
379 |
00000001 01111011 |
Pojawia się też cała tablica znaków specjalnych np. „różnorodne symbole” Unicode zajmują pozycje U+2600—26FF (będą zapisywane różnie(!) w zależności od kodowania – utf-8, utf-16 czy utf-32) np. ☂, ☔, ♥, ♡, ☸ (o kubernetes! – żarcik 😛 )
Skąd się tu wzięły emoji?
Znaki graficzne, ideogramy zwane emoji pojawiły się poraz pierwszy w Japonii. Dzięki rozpowszechnieniu w social mediach, pierwsze emoji zostały wprowadzone w 2010 w wersji Unicode 6.0 i były oznaczone kodami U+1F600—1F64F. Obecnie są różnie wspierne i mogą się różnić wyglądem w zależności od miejsca wyświetlania (urządzenia, przeglądarki, czy aplikacji – fb, twitter etc).
Emoji raw vs w kolorze

| emoji | unicode nr | hex | dec | bin |
| 😘 | U+1F618 | F0 9F 98 98 | 4036991128 | 11110000 10011111 10011000 10011000 |
| 👁 | U+1F441 | F0 9F 91 81 | 4036989313 | 11110000 10011111 10010001 10000001 |
| 🌸 | U+1F338 | F0 9F 8C B8 | 4036988088 | 11110000 10011111 10001100 10111000 |
| 🦄 | U+1F984 | F0 9F A6 84 | 4036994692 | 11110000 10011111 10100110 10000100 |
UTF-16
Znaki w UTF-16 przyjmują 2 bajty lub 4 bajty. Pierwsza część tabeli Unicode jest kodowana właśnie przy użyciu 2 bajtów, a następna za pomocą 4 bajtów. UTF-16 podobnie jak UTF-8 ma zmienną długość symbolu, ale jest jednak mniej skomplikowany, dlatego można go nazwać kompromisem pomiędzy UTF-8 a UTF-32. Używany najczęściej przy kodowaniu języków azjatyckich.
UTF-32
UTF-32 wykorzystuje stałą, 32-bitową długość czyli 4 bajty dla każdego znaku. Jego wadą jest zużycie dużej ilości pamięci, gdyż każdy znak ma zawsze cztery bajty.
Duża litera A czyli 65 miejsce w tabeli otrzymuje zapis 00000000 00000000 00000000 0100 0001 w systemie binarnym. Dla porównania w UTF-8 zapis wyglądałby tak: 0100 0001.
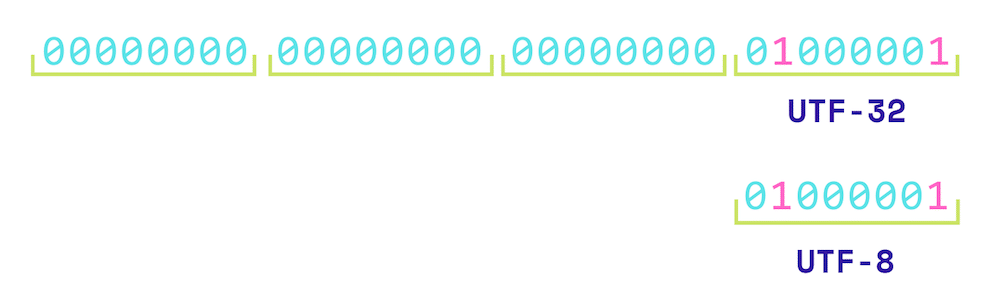
W przypadku najbardziej popularnych znaków (np. pierwsze 128 znaków ASCII) marnowane są bajty, bo przynajmniej połowa bitów pozostaje zerowa. Niepotrzebnie wydłuża się wielkość zapisu znaków. Z drugiej strony każdy znak ma taką samą długość 4 bajtów, co ułatwia znalezienie danego symbolu w ciągu. Ze względu na długość UTF-32 jest mało popularnym systemem stosowanym zwykle w pamięci operacyjnej.
UWAGA: Mała prywata!
Lubisz FlyNerda? Wpadasz tu czasem na posty takie jak przewodniki po front-endzie czy wymaganiach junior Python developera?
Wkrótce moje urodziny, z tej okazji możecie zrobić mi prezent i Alexowi.
Alex urodził się w czerwcu, jest synem moich dobrych znajomych, sąsiadów, którzy do tego w życiu zawsze byli dla mnie wzorem (Magda jest onkologiem dziecięcym, Paweł pracuje w bliskiej mi organizacji – stowarzyszeniu Otwarte Klatki). Zostałam ciocią!
W dniu, kiedy Alex skończył dokładnie pięć tygodni, zdiagnozowano u niego rdzeniowy zanik mięśni typu I (SMA I), chorobą do niedawna właściwie beznadziejną. Jednak dzięki szybkiej reakcji rodziców otrzymuje już lek, teraz konieczna jest stała rehabilitacja. Oprócz tego czekamy na kosztowną, ale skuteczną terapię genową.
Możecie wyrazić sympatię do mnie, dając mi „urodzinowy prezent”, robiąc coś dobrego dorzucając się do zbiórki dla Alexa! ❤️
Każdy teraz dorzuca się do zbiórki na moje urodzin 🎂 (3 października). Zbieram dla Alexa – synka znajomych, u którego…
Posted by FlyNerd.pl – blog o programowaniu on Thursday, September 26, 2019
Dzięki za wpis, niby człowiek coś wie, a zawsze się dowie czegoś nowego
„o kubernetes!” – uwielbiam cię! 😀
Ten wpis powinen się nazywać KODOWANIE ZNAKÓW DLA OPORNYCH, bo wszystko zrozumiałam XD
Soczysty i treściwy wpis, dzięki bardzo
Heh, przypomniał mi się pierwszy semestr i ASK. Prowadzący był kosą, i do tego ciętą na kodowanie właśnie. Co więcej, poza wykładem prowadził też ćwiczenia, w konsekwencji 90% ludzi nawet nie mogło podejść do egzaminu.
Z perspektywy czasu cieszę się, że zdałem zerówkę, bo nie wiem czy przetrwałbym kolejne podejścia, które stawały się coraz gorsze.
PS: Luźna dygresja, jeżeli miałabyś wybierać pomiędzy informatyką II stopnia na Politechnice Poznańskiej albo Uniwersytecie w tym samym mieście. To którą opcję byś wybrała i dlaczego?
Jeżeli między Informatyką na Wydziale Informatyki, a Informatyką na Wydziale Matematyki i Informatyki wybrałabym prawdopodobnie Politechnikę. Może systemy wspomagania decyzji, chociaż, są naprawdę różne specki i ciężko powiedzieć. O UAMie nie słyszałam za bardzo pozytywów, poza faktem, że można zrobić magister inżynier infy za jednym zamachem i głównie tam szły osoby, które na pierwszym stopniu nie miały inż. Nie wiem czy ostatnie 2-3 lata coś zmieniły, ale do UAMu zniechęca mnie też chaos organizacyjny, problemy z USOSem (wieczny brak miejsc na moduły, które są obowiązkowe, ale okazuje się, że nie da się zapisać, bo problemy systemu, potem cały rok musi chodzić po dziekanacie licząc, że jednak uda się dograć ECTSy). Na PP nie zdażyło mi się to nigdy, na UAMie jest to powszechny problem, który powtarza się na wszystkich wydziałach niezależnie od kierunku (na bioinfie dość znany problem).
Z tego co doczytałem to kodowanie znaku 2 i więcej bajtowego w systemie utf-8 wymaga ustawienia pewnych bitów. Przykładowo przy 2 bajtowym znaku, kodowanie binarne wygląda następująco: 110x xxxx | 10xx xxxx. Jeśli dobrze to zrozumiałem, to masz mały błąd w konwersji w tabelce. Ogólnie to fajnie wytłumaczone, dzięki za wpis 🙂
Jak to mówił Dave z ameryki: good 🙂
Odniosę się do tabeli bezpośrednio pod „Emoji raw vs w kolorze”.
Weźmy pierwszy wpis dla emoji: U+1F618
1. Warto nadmienić, że każdy code point w Unicode posiada swoją unikalną wartość, tutaj podaną w hex: „1F618”
2. Natomiast to co podajesz w kolumnach „hex”, „dec” oraz „bin” są to wartości już zakodowane zgodnie ze standardem UTF-8. Stąd te dwa hexy są różne :]
Może warto dodać krótki opis tej tabelki:]
Nigdy z tym nie przepadałem
Pani artykuły to dzieła sztuki.
Spotkałem się z polskimi znakami złożonymi z dwóch znaków. Aby usunąć taką literę musimy wcisnąć Backspace dwukrotnie. Najpierw usuwamy akcent a następnie literę. wkleję tu dwa przykłady: ę ó. Nie jestem pewien czy po ich skopiowaniu i wklejeniu do notatnika nadal będą tak się zachowywać. Czasem wyszukiwarki wyświetlają inną liczbę wyników dla dwóch różnych metod wprowadzania polskich znaków. Podobno obie metody są zgodne z normami. Czy ktoś może wyjaśnić ten fenomen? Przekopałem trochę sieć ale nie znalazłem żadnych informacji na ten temat.
Został jeszcze problem w UTF-16 i UTF-32 z bigendian i little endian. Co daje nowe kodowana UTF-16 LE, UTF-16 BE, UTF-32 LE i UTF-32 BE. Ponadto znaki zawierają sekwencje zmiany kierunku pisania tekstu od lewej do prawej (LTR) i (RTL) stąd posługiwanie się pojedynczymi znakami w dowolnym kodowaniu UTF robi się skomplikowane. Nie mówiąc o tym, że polskie znaki diakrytyczne można zapisać „dwojako”, np. ą jako 0x0105 jak również 0x2DB 0x0041. Weź tu odgadnij, że to ten sam znak.
Ciekawy artykuł.
Zrobiłem wyszukiwarkę słów w bazie danych. Wykorzystuję FULL TEXT SEARCH w trybie BOOLEAN.
Szukam rozwiązania aby przykładowo ze słowa „wąż” kodowanego w UNICODE pozyskać wszystkie inne kombinacje tego wyrazu napisane częściowo tylko znakami ASCII. Te kombinacje są następujące: waz, wąz, waż.
Tak samo dla słowa „żółw”, są kombinacje : „zółw, zołw, zolw, zólw, żólw”.
Chciałbym aby to rozwiązanie było uniwersalne i działało też dla rumuńskiego słowa giga – gîgă, or hiszpańskiego słowa ołówek – lápiz.
no to w tle historycznym powinno się dodać choćby dwa zdania o czasach komputerów 8bit – czyli polskich literkach w amstrad, atari, comodore i zx sppectrum. A także już z ery pc’tów o latin i mazowia (a także paru innych)
Fajnie wytłumaczone,
dziękuję i pozdrawiam 🙂